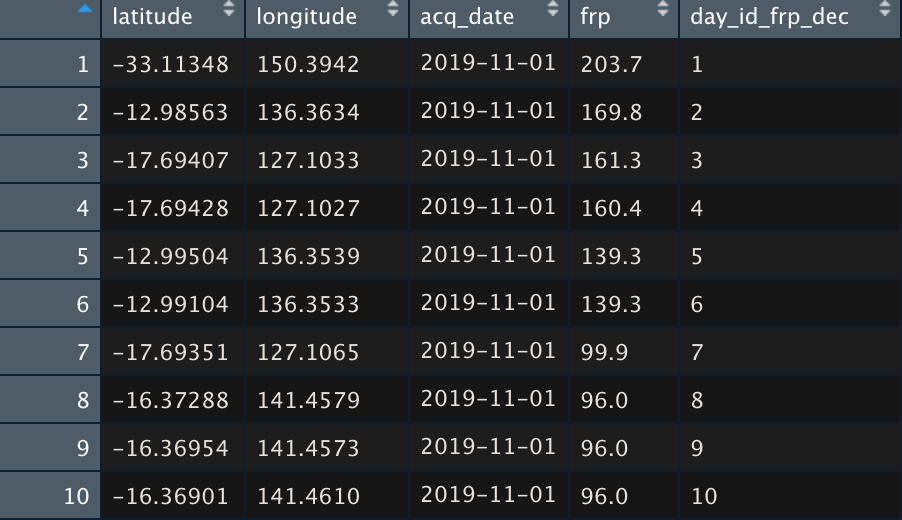
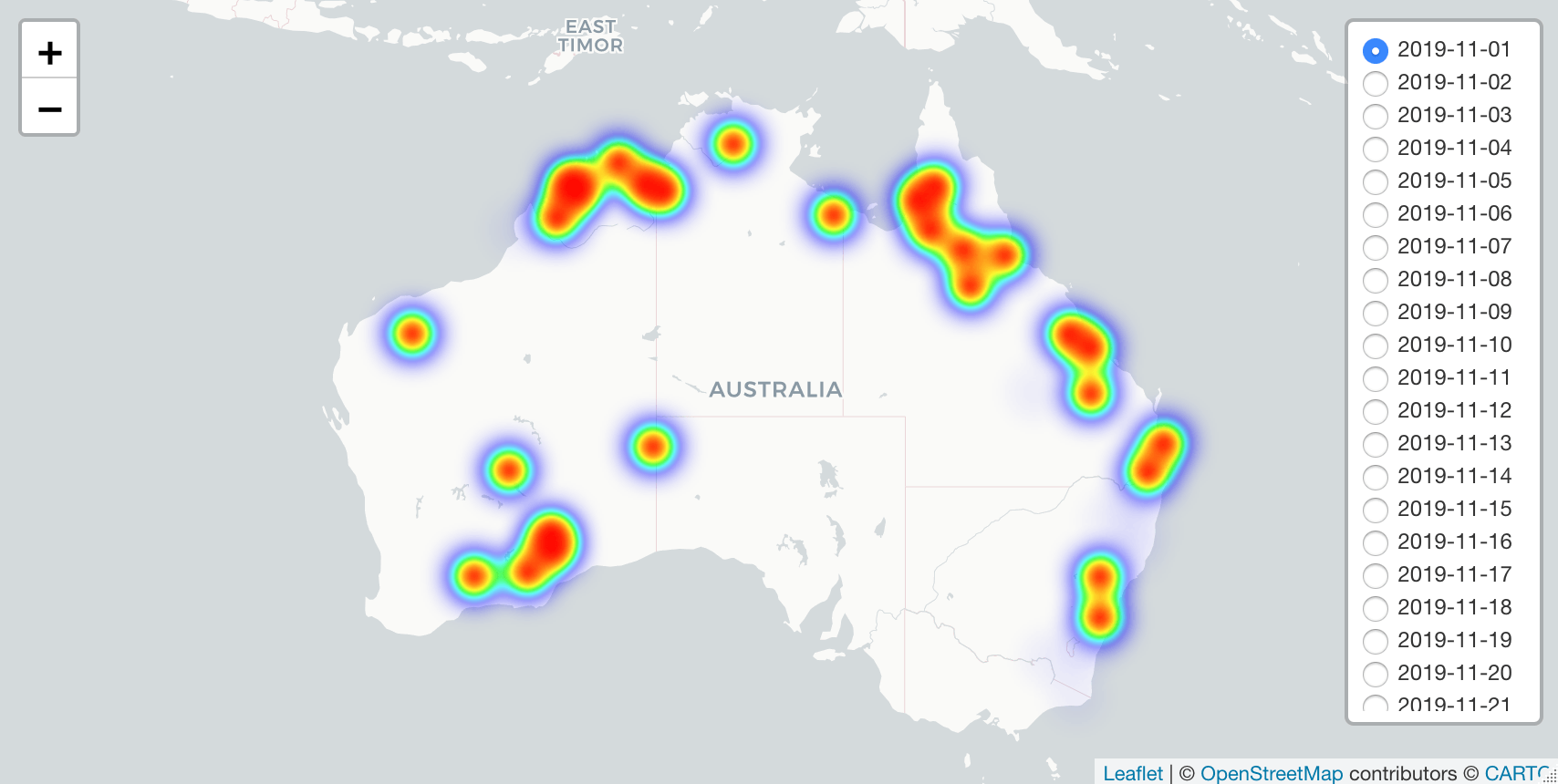
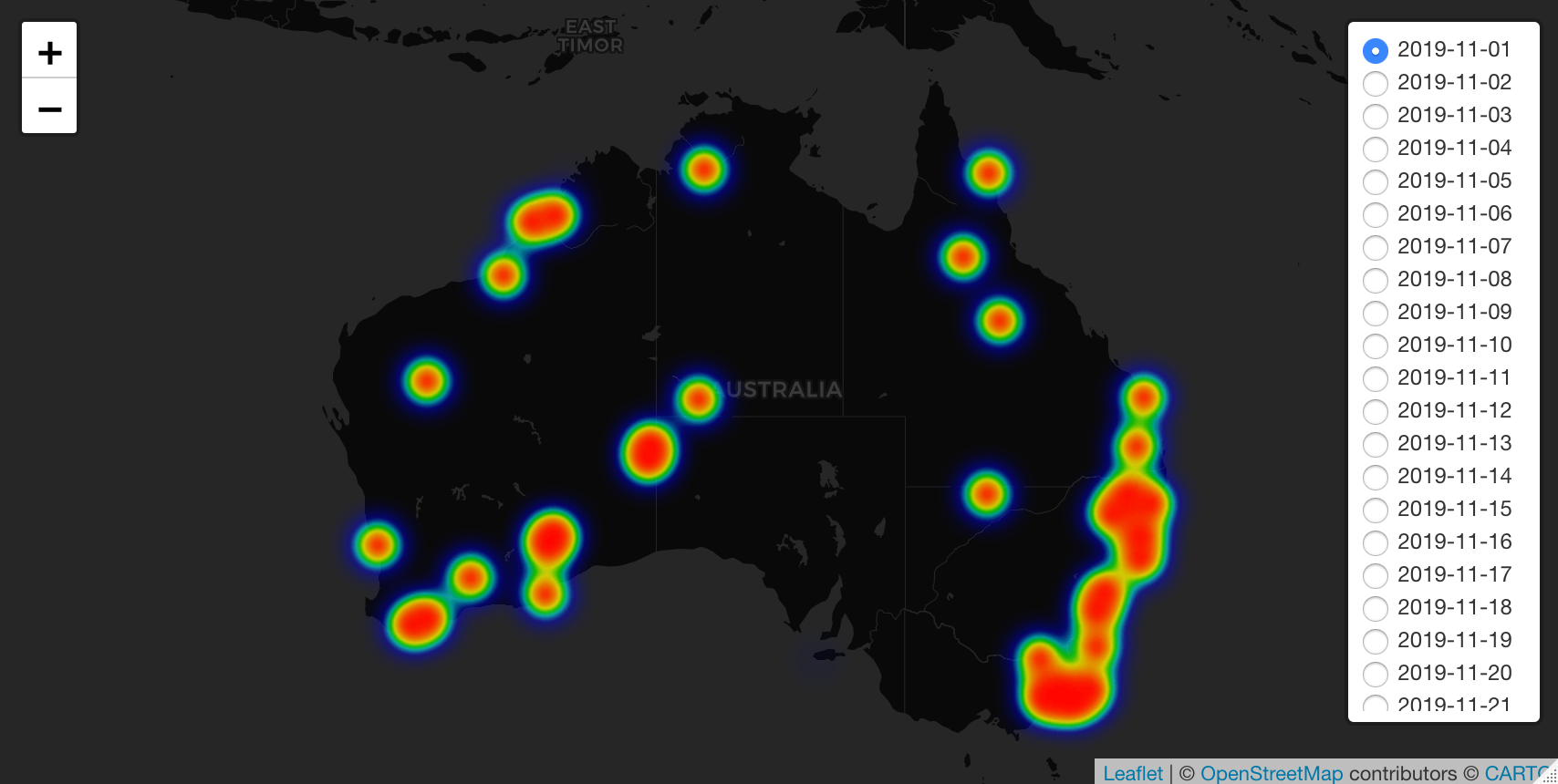
Research Question - what better to understand
When further investigating this phenomenon off course al lot of information and opinions can be founds in the media. As it's never been in my character to hold an opinion agains someone, but is in my nature to form one based of facts. Hence, I decided to analyse this phenomenon properly when back in The Netherlands. At that time I formed a clear sense of what I was going to study and formulated the following research question:
1. How did the wild fires develop in Australia during the bushfire season of 2019/2020?
Data collection & manipulation
Over the years I have developed a particular interest in geo-spatial analysis. With the use of R
(language and environment for statistical computing and graphics) I will be using data science technique and methods like descriptive statistics, geo-spatial analysis
and multi-variate analysis. The insights can be used to track and analyse how the bushfires developed across Australia, and possible give insight towards fire fighting capacity decisions. Where, I am well aware that my knowledge is relatively limited compared to local (Australian) knowledge. Hopefully this research helps as a first introduction in explaining the bushfires for people less familiar with this phenomenon. Similar to my situation, before travelling to Australia.
Before starting to analyse the bushfire data. We need to find out how to get acces to this data. After some preliminary desk research I foresaw two data science techniques for collecting the data.
- Web-scraping the data from sources like wikipedia.
- Using NASA's satellite data with heat detection algorithm
An easy choice
Webscraping: although I'am a partizan of fast prototyping in my code and initially pay less attention to re-usability of it (I usually do that after finalising the project) web scraping as - I once again discovered in my Corona related posts- can be a a time consuming and ordeal experience. Digging trough the source HTML of sites and transforming the data into workable tables and objects in your RStudio can get messy. And then....NASA satellite data! As somewhat of a geek (or actually - full on one) I got very excited about the possibility of working with Satellite data from NASA!. (you guess which one - were going to use in research) . Yup, NASA data - it is!
Meta Data: what data is available
The further I got in the NASA documentation - I started realising that utilising this option might be achievable. Where, as with every post I take into account that readers do not need to have deep understanding about statistical or data science concepts.
The data can be found on the
NASA's active fire site. A quick scan of this page provides us the information that data from the satellite is detected across the globe in the following regions.
- Alaska
- Conterminous US and Hawaii
- Central America
- South America
- Europe
- Northern and Central Africa
- Southern Africa
- Russia and Asia
- South Asia
- South East Asia
- Australia and New Zealand
Limitation / Scoping
For this analysis we are interested in the ' Australia and New Sealand' data. (Keep in mind for future research, how great is - knowing that the data is also available for all other regions).
Evaluating Data Sources - a step back to get the full picture
While reading through the site I also found that NASA uses different sensors (instruments) and algorithms onboard different satellites for (fire) detection purposes, being VIRSS and MODIS.
Without reproducing the entire contents of both source documents, I will try to give a short(er) and simplified summary. I hope I succeed in that. Please note that I'am literally not a (space)rocket scientist, but am completely fascinated by trying to make sense of the satellites, the instruments onboard and the data they produce.
So, let's have a closer look at the two!
"It collects visible and infrared imagery and global observations of the land, atmosphere, cryosphere and oceans".(https://www.jpss.noaa.gov/mission_and_instruments.html, 2020 April)
Together with the other instruments it collects data about "atmospheric, terrestrial and oceanic conditions, including sea and land surface temperatures, vegetation, clouds, rainfall, snow and ice cover, fire locations and smoke plumes, atmospheric temperature, water vapor and ozone" (https://www.jpss.noaa.gov/mission_and_instruments.html, 2020 April)
The other instruments (next to VIIRS) consist of:
ATM:
The Advanced Technology Microwave Sounder (ATMS) instrument is a next generation cross-track microwave sounder that of special interest for '...weather and climate related topics based on atmospheric temperature and moisture profiles'.
(https://www.jpss.noaa.gov/mission_and_instruments.html, 2020 April)
CERES: Clouds and the Earth's Radiant Energy System
special interest for studying "...solar energy reflected by Earth, the heat the planet emits, and the role of clouds in that process". (https://www.jpss.noaa.gov/mission_and_instruments.html, 2020 April)
CrIS: Cross-track Infrared Sounder
special interest for studying: "...detailed atmospheric temperature and moisture observations for weather and climate applications."
(https://www.jpss.noaa.gov/mission_and_instruments.html, 2020 April)
OMPS: Ozone Mapping and Profiler Suite
special interest for investigating "the health of the ozone layer and measures the concentration of ozone in the Earth's atmosphere".
(https://www.jpss.noaa.gov/mission_and_instruments.html, 2020 April)
Below you see an image of the Joint Polar Satellite System (JPSS).
Taken from (https://www.jpss.noaa.gov/satellite_gallery.html#gallery-14, 2020 April)
*please note that I couldn't find anything on sharing the image. Hoping its ok to share with source. If not will be more than willing to remove it from here