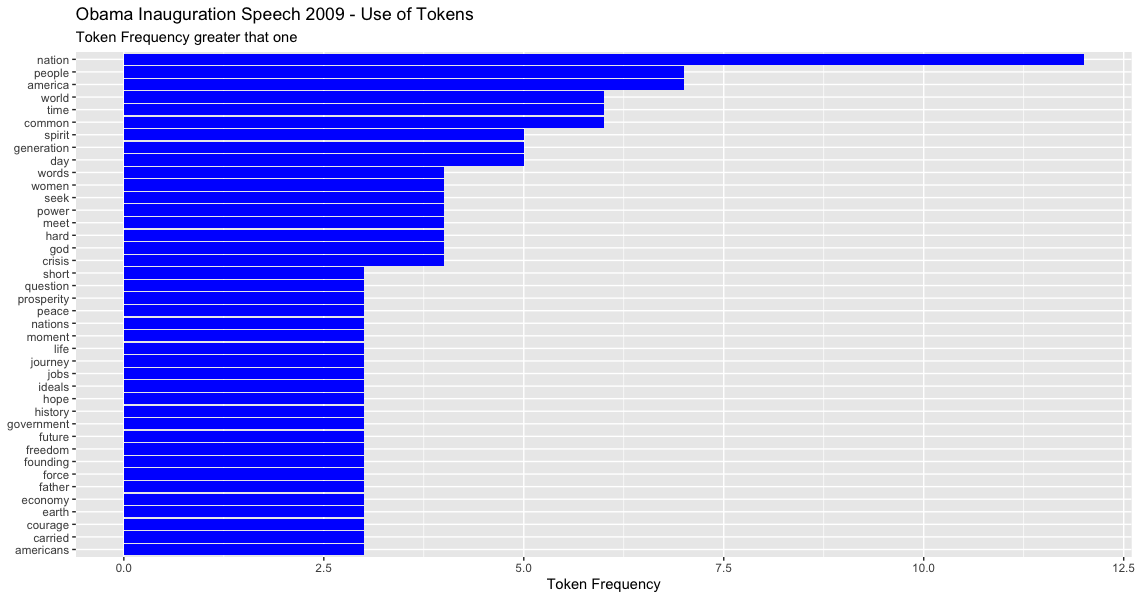
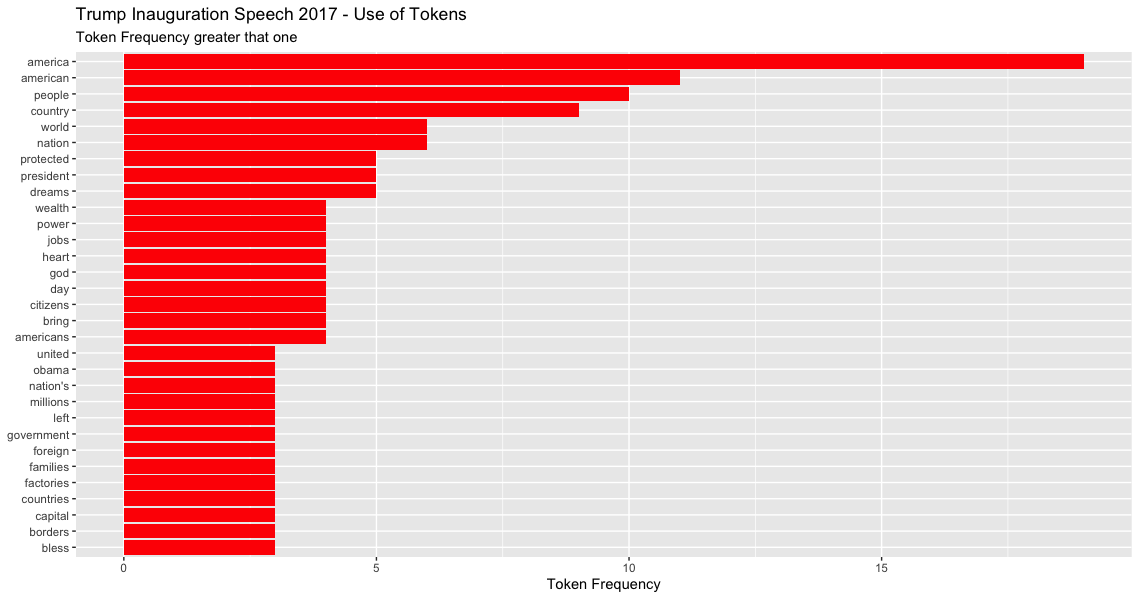
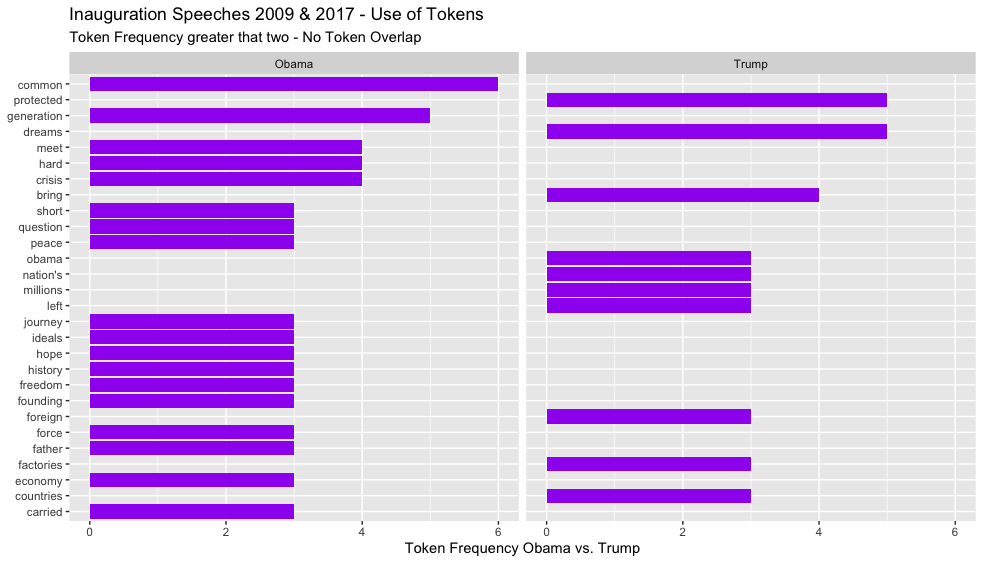
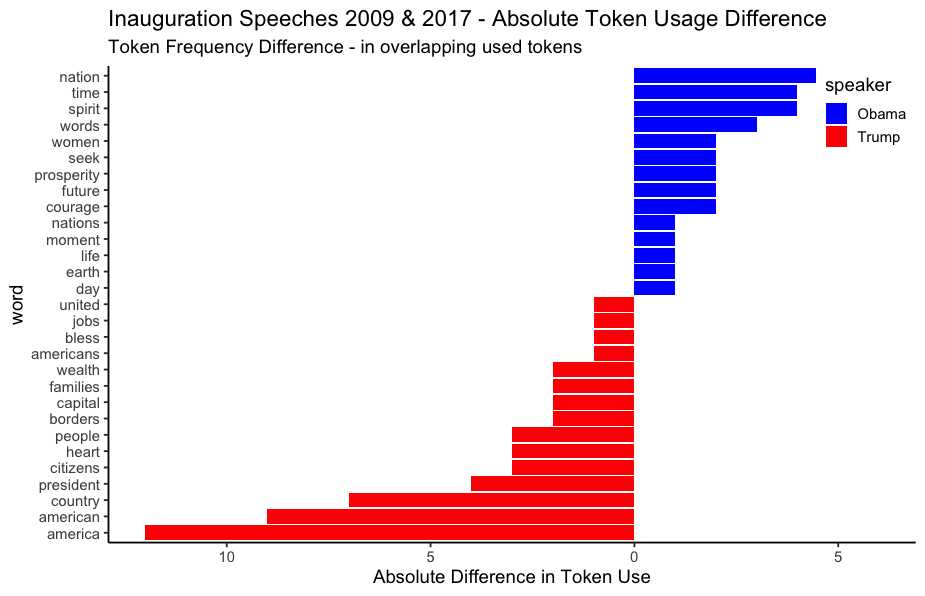
Topic modeling (TM)
Topic modelling
is a set of techniques for automatically organising, understanding, searching, and summarising large amounts of texts.
It can help with the following challenges:
- Identifying clusters of what is being said
- allocating new input to those clusters
Latent Dirichlet Allocation (LDA)
Within Topic Modelling, Latent Dirichlet Allocation (LDA) is an important concept. To help you in discussion with data scientists, I'll provide you with a simplified overview. Hopefully resulting in greater knowledge about key concepts.
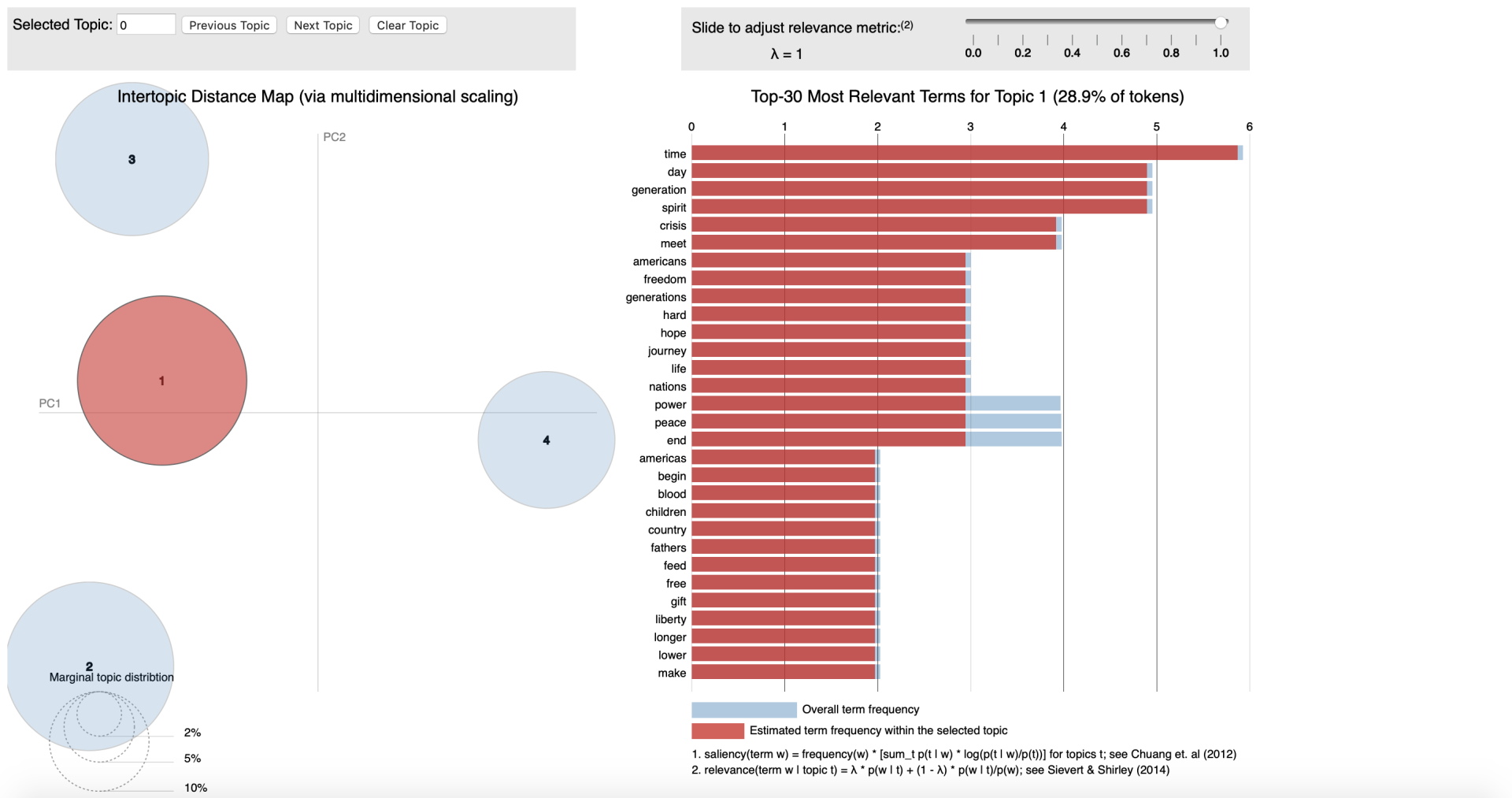
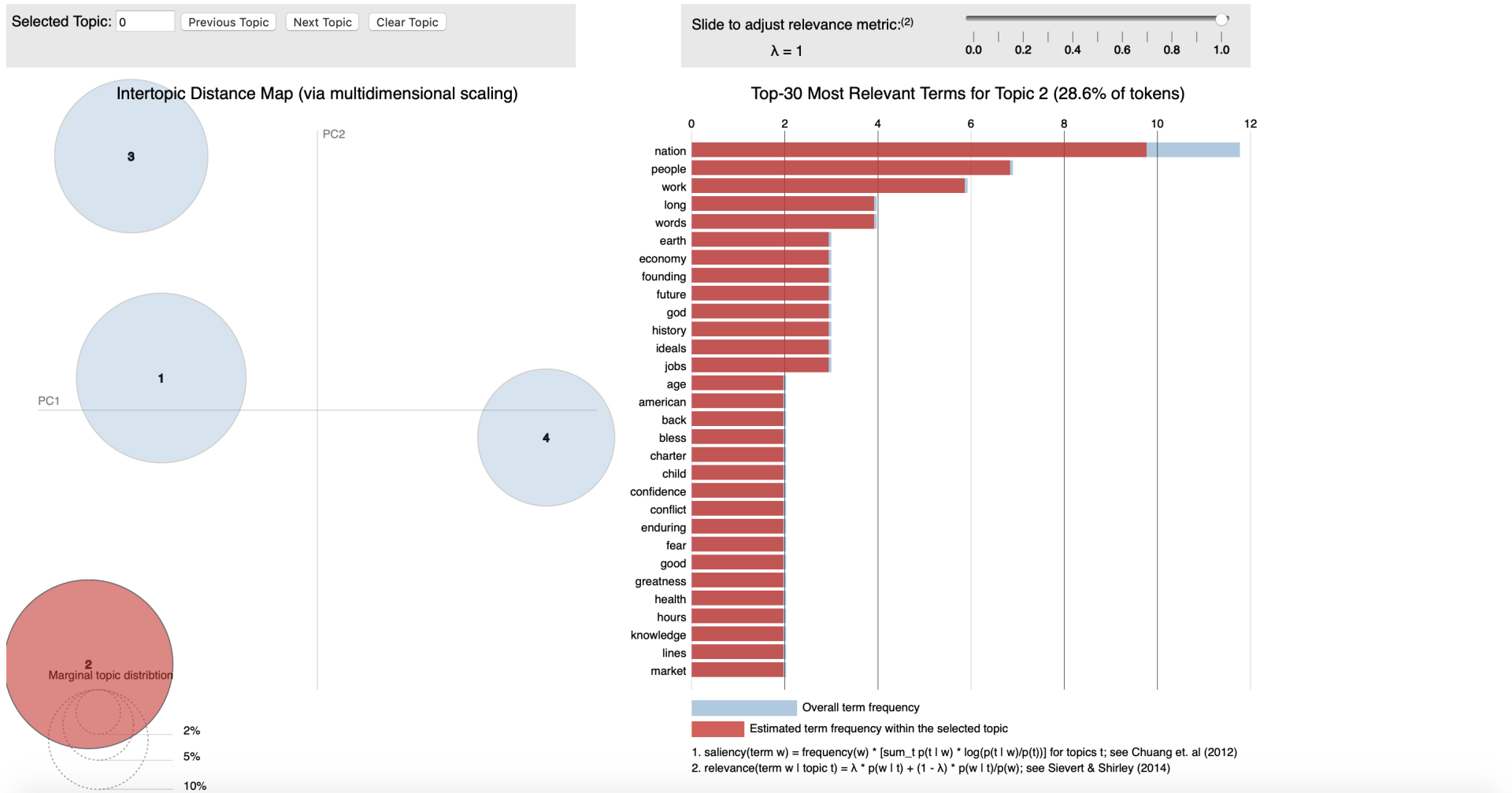
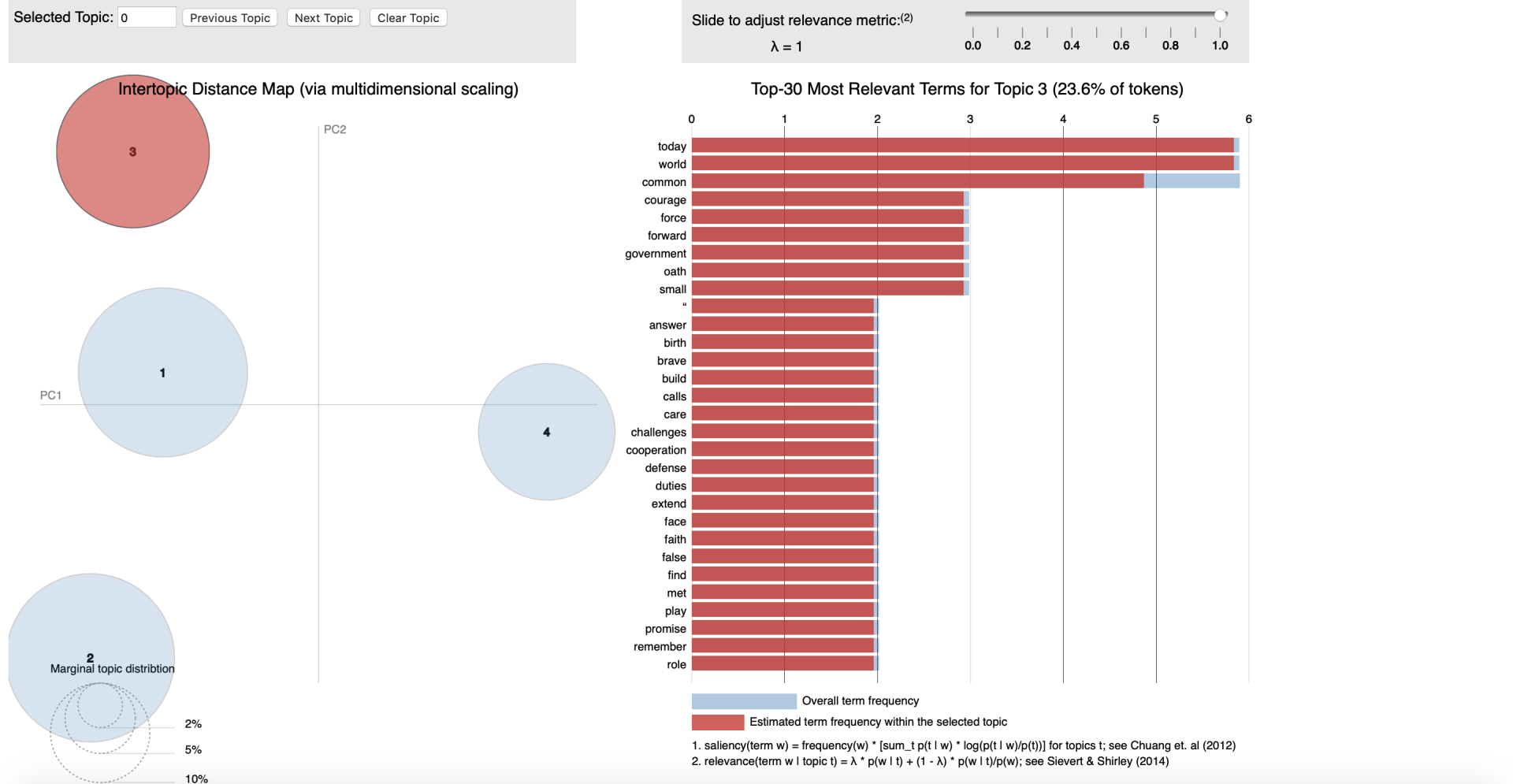
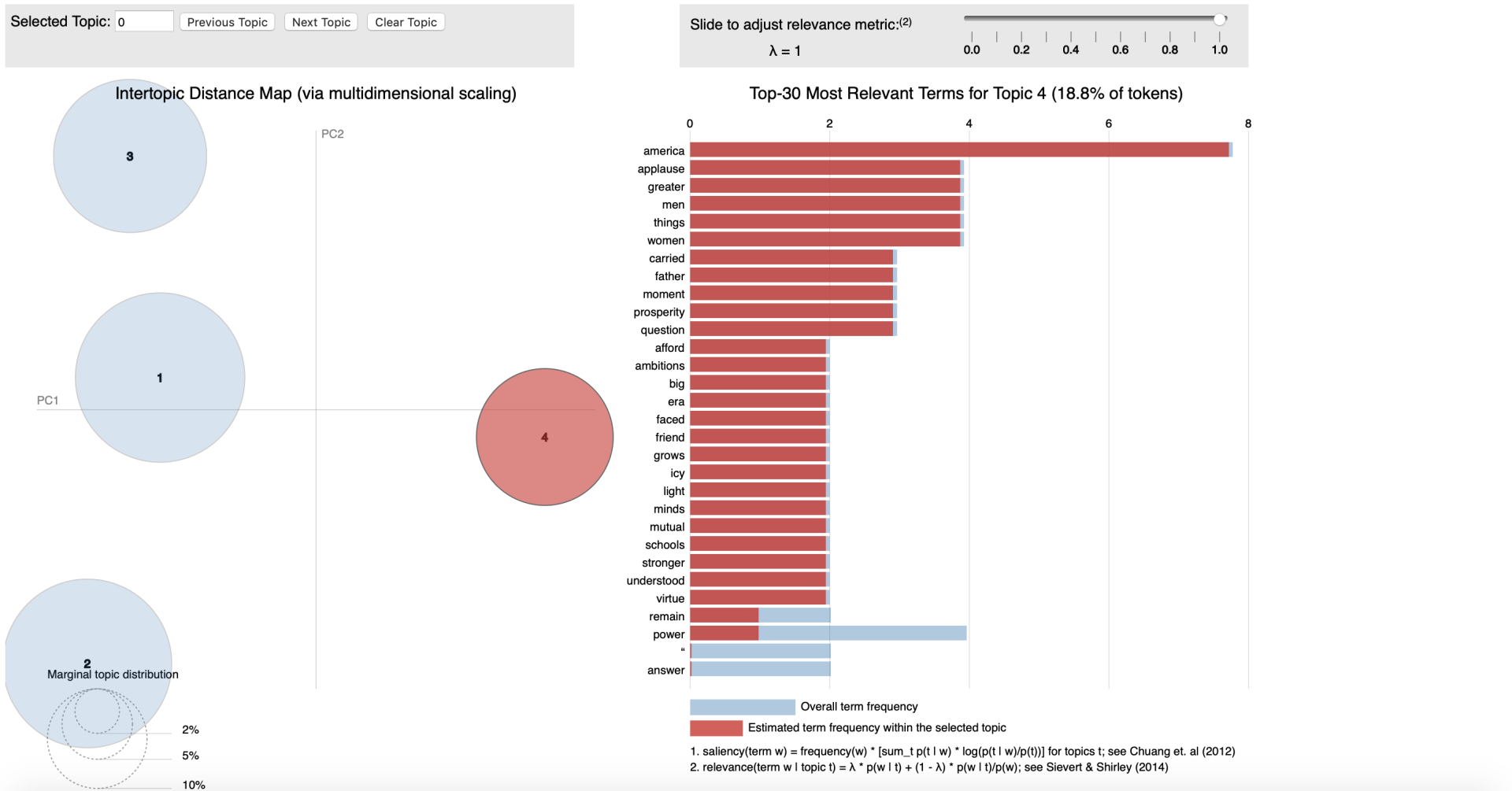
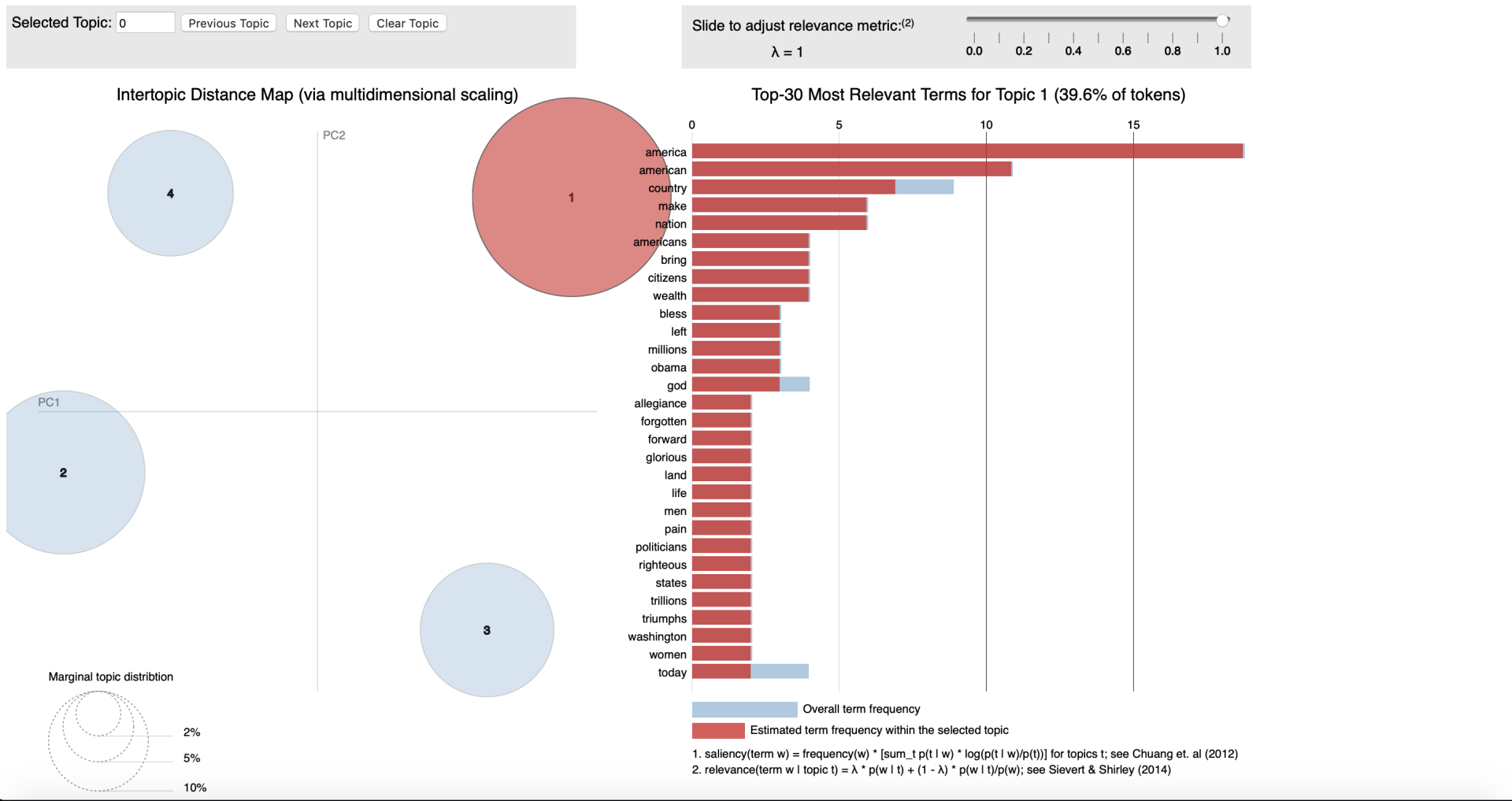
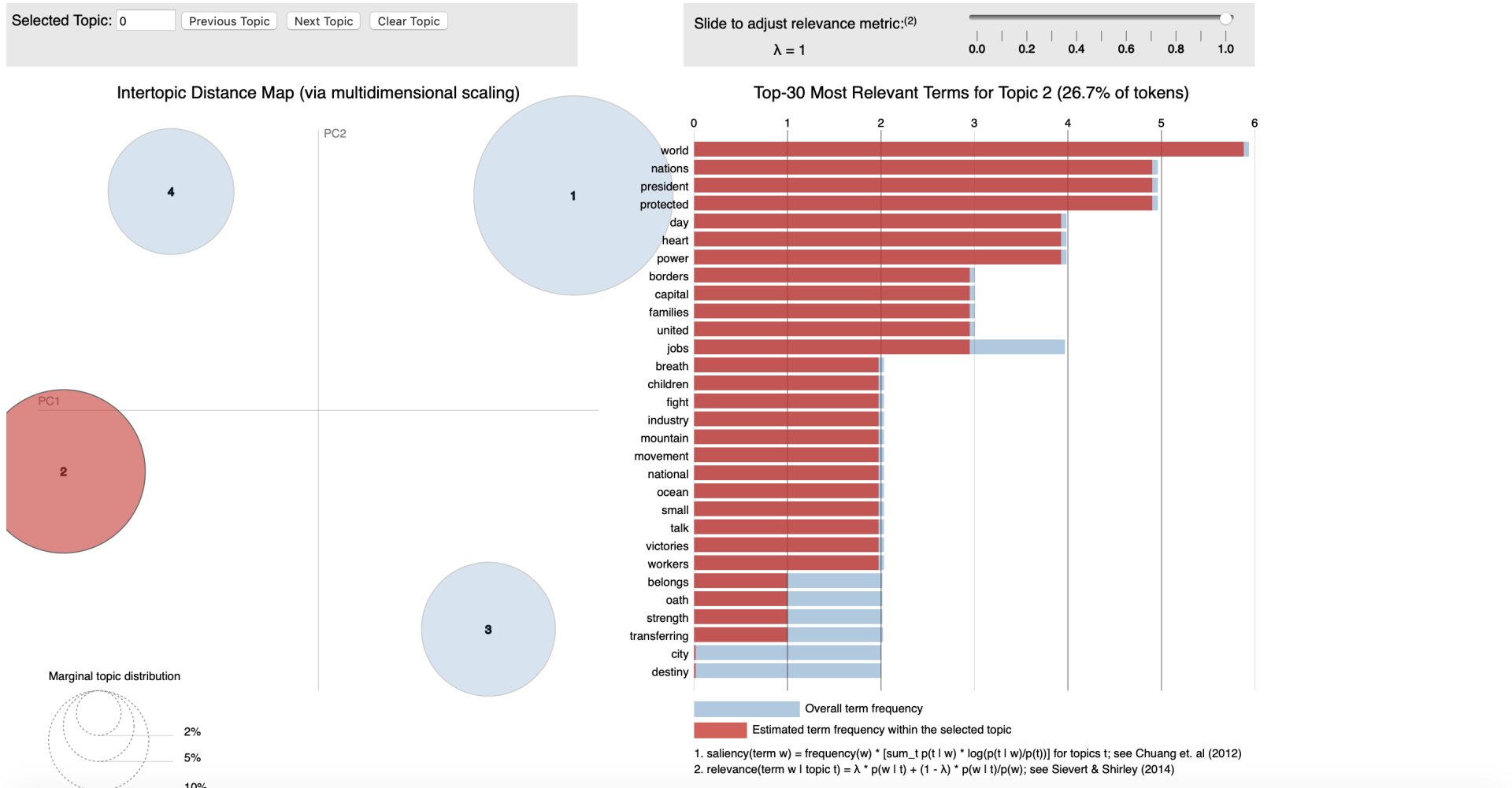
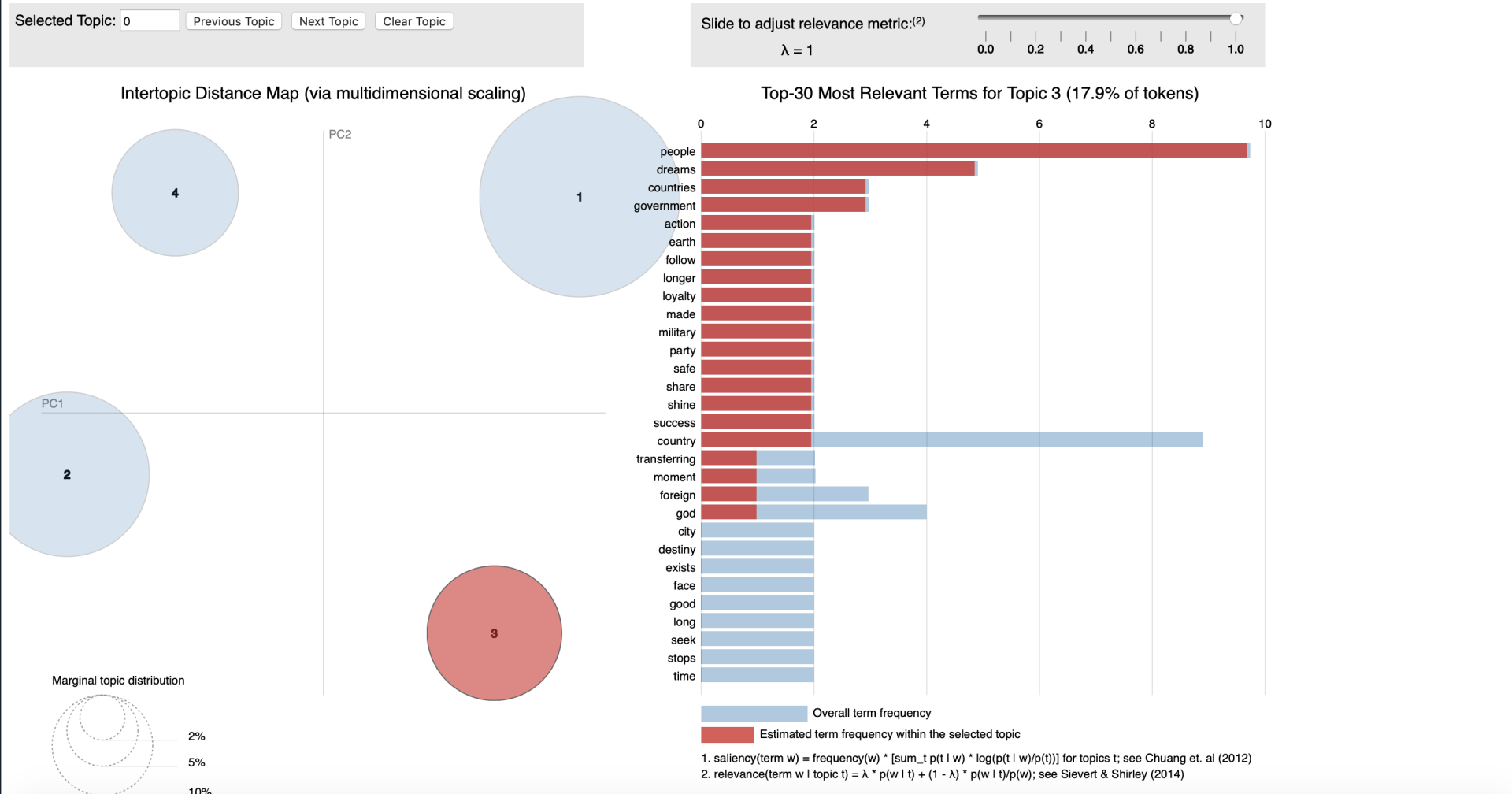
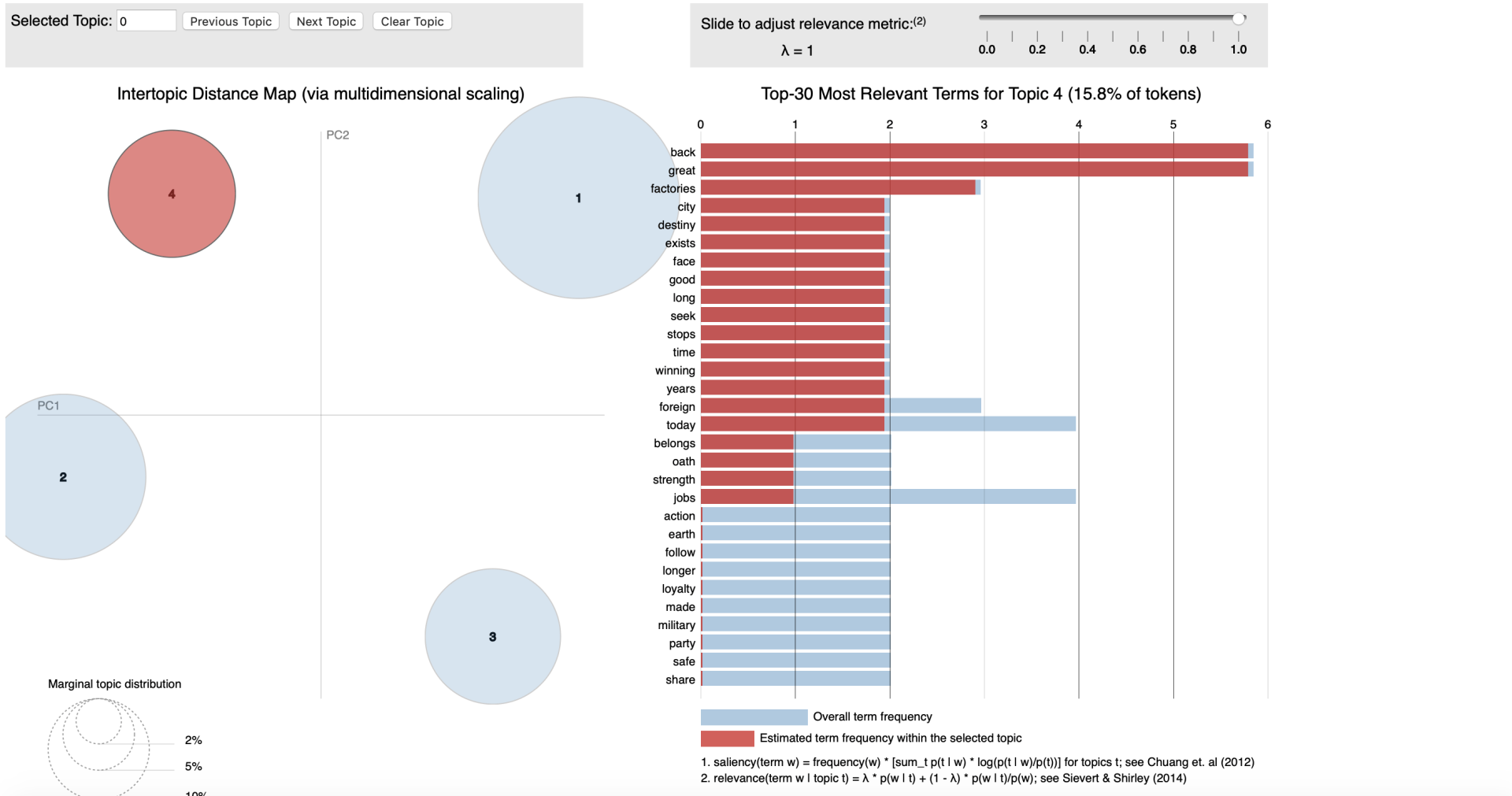
Conceptually LDA is a technique where we transform plain text into data table. Here by counting the occurrence of different words in the text and allocating them to a topic (cluster) - we will be able to calculate a probability for each word that it is related to that topic.
An example here could be if we would feed the LDA algorithm emails between a manager an a data scientist it would be thinkable that we could detect different Idiolects (set of words and intonation typical to an individual) between the two functions. Solely for clarification purposes I'm labelling the manager as result driven and the data scientist as technique driven. Hence words as timing, costs or deliverables would (cor)relate to a cluster that we could label "
management" and words as model, hypothesis and statistics support would (cor)relate to a cluster that we could label "technique". Interestingly we would also be able to discover which are less related to one person when we have 'chit-chat' in our emails with words weather, family or weekend we could label that as '
informal chats'. The latter type of classification is form the perspective of text analysis more interesting as solely performing a machine learning endeavour to find topic of mangers vs those of data scientist mighty not be worth the effort. As we're aiming to find the underlying topics, not the persons.
As the mathematical concepts are quite complex behind LDA, I'll provide you with the key steps in process.
- Set the number of clusters / topic we want to find. (can be calculated statistically or hypothesis based)
- Calculate word, topic correlation (based on Dirichlet distributions)
- Calculate topic, document correlation (based on Dirichlet distributions)
- Re-iterate to re-calculate word, topic correlation (based on Dirichlet distributions)
Where it is first done randomly in a simplified manner to set a benchmark and test set for the final part to score the model output. This is somewhat oversimplification of the statistical part, nevertheless I hope it gives insights on how the process works.