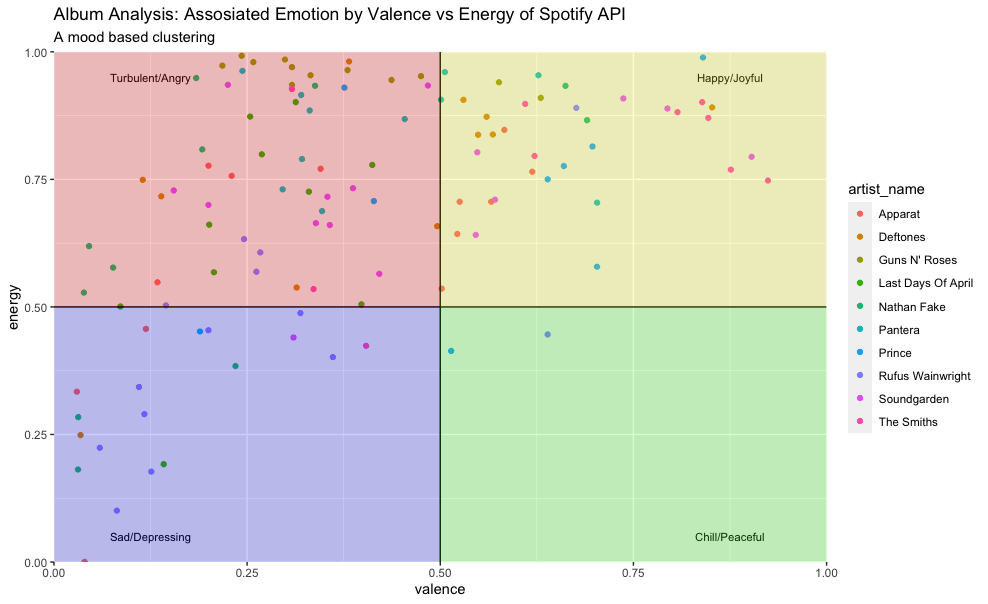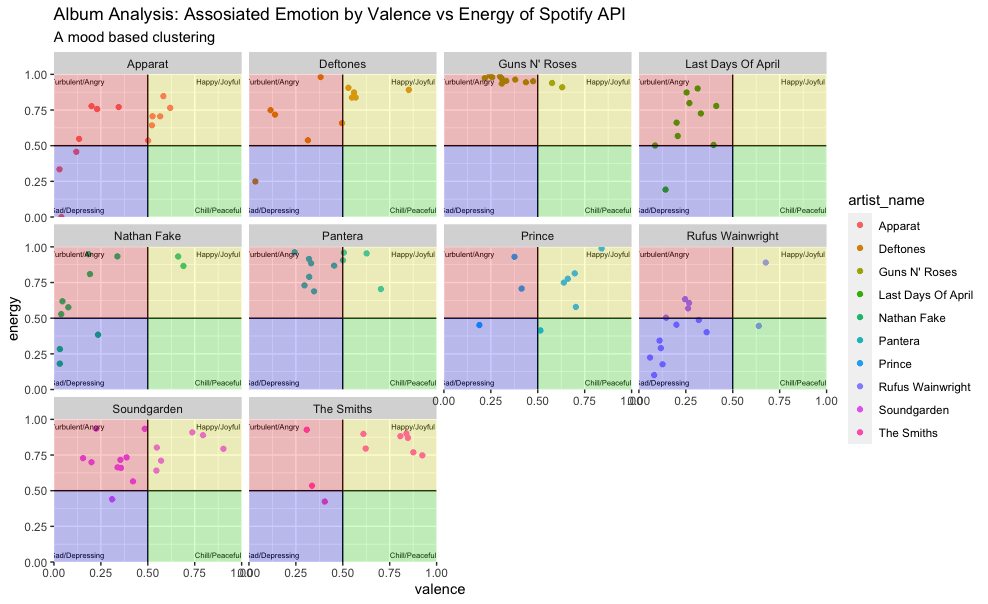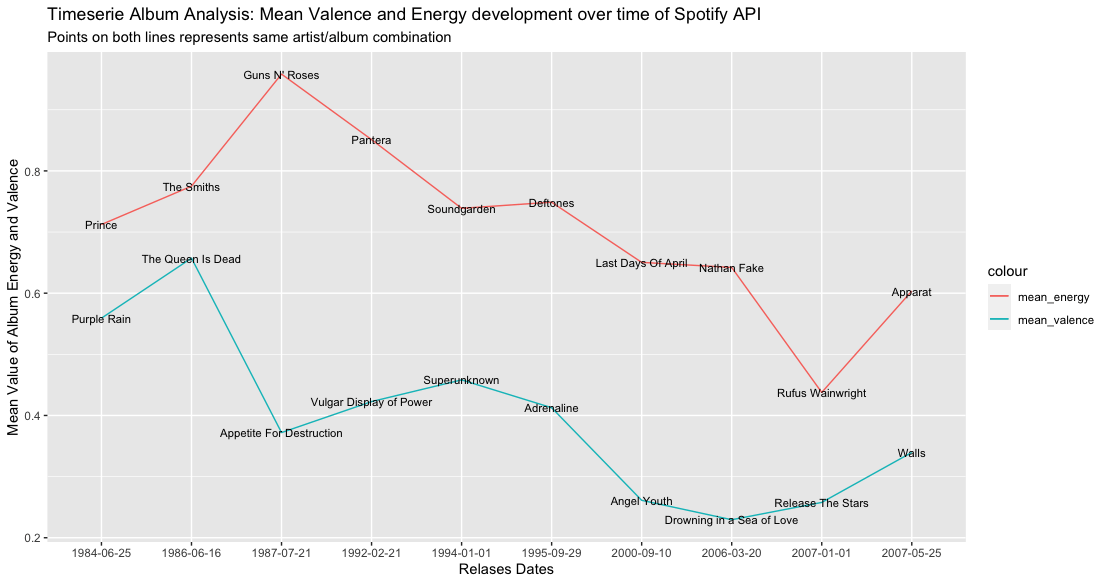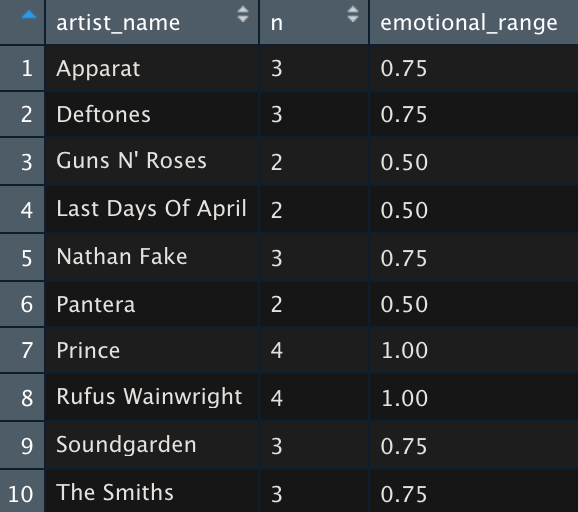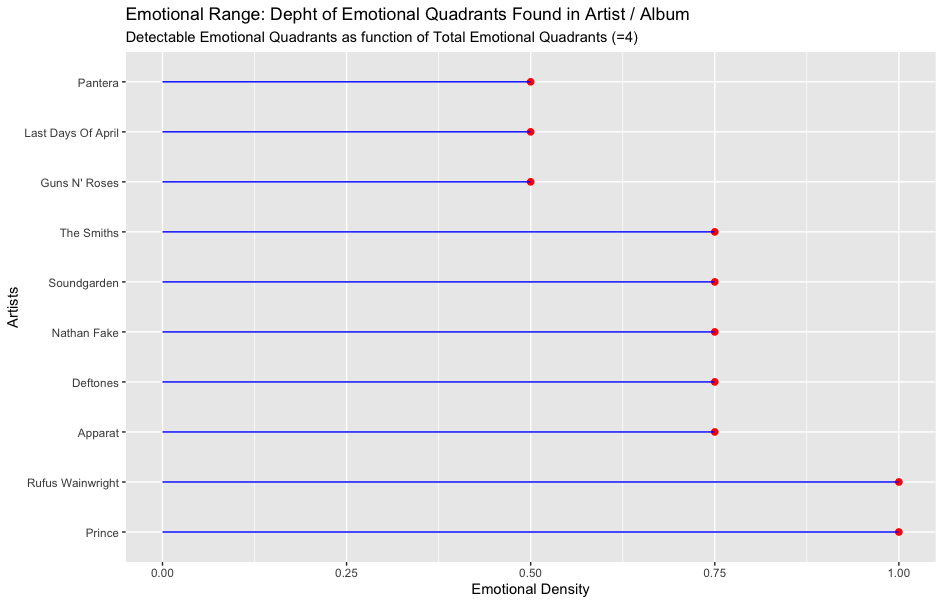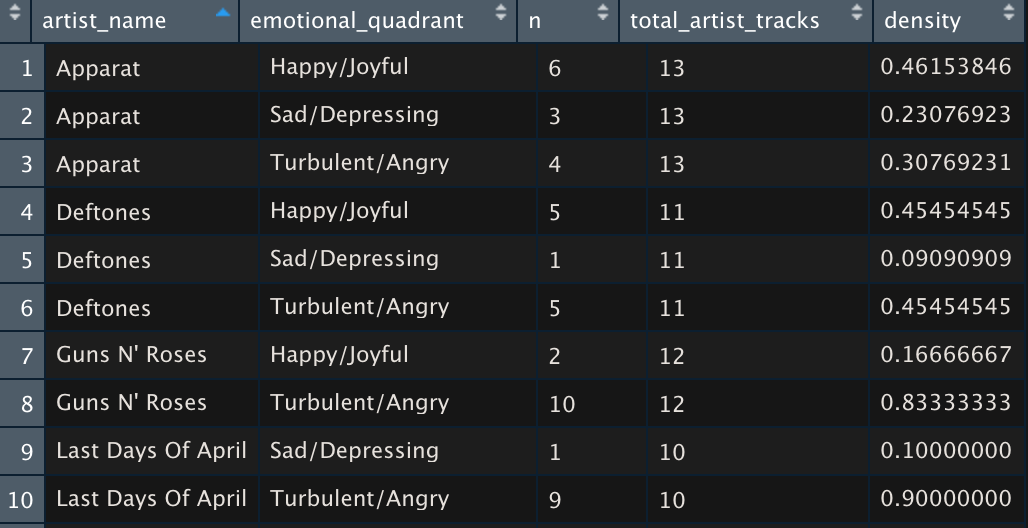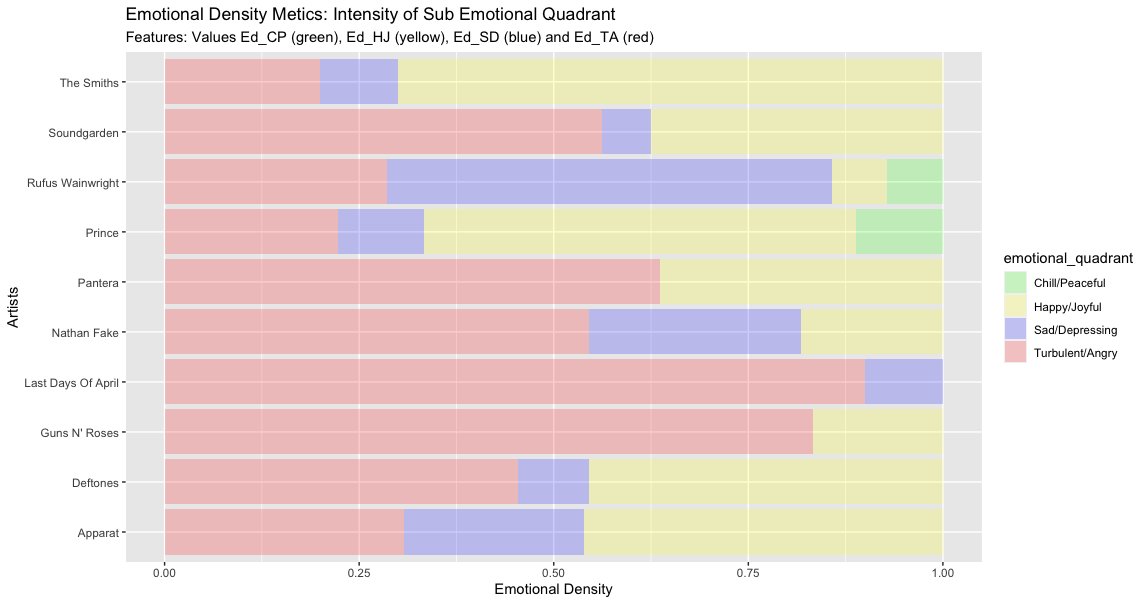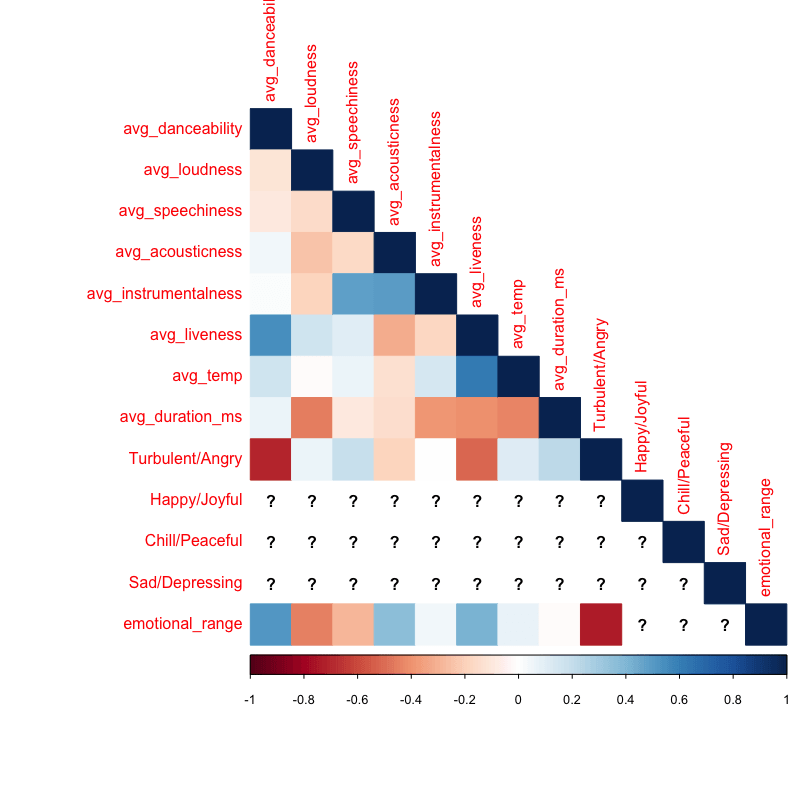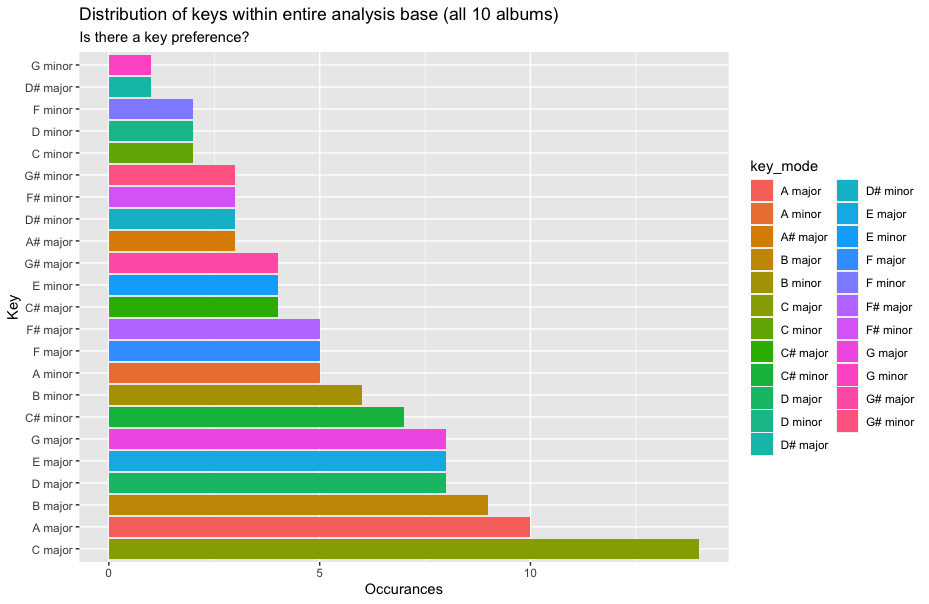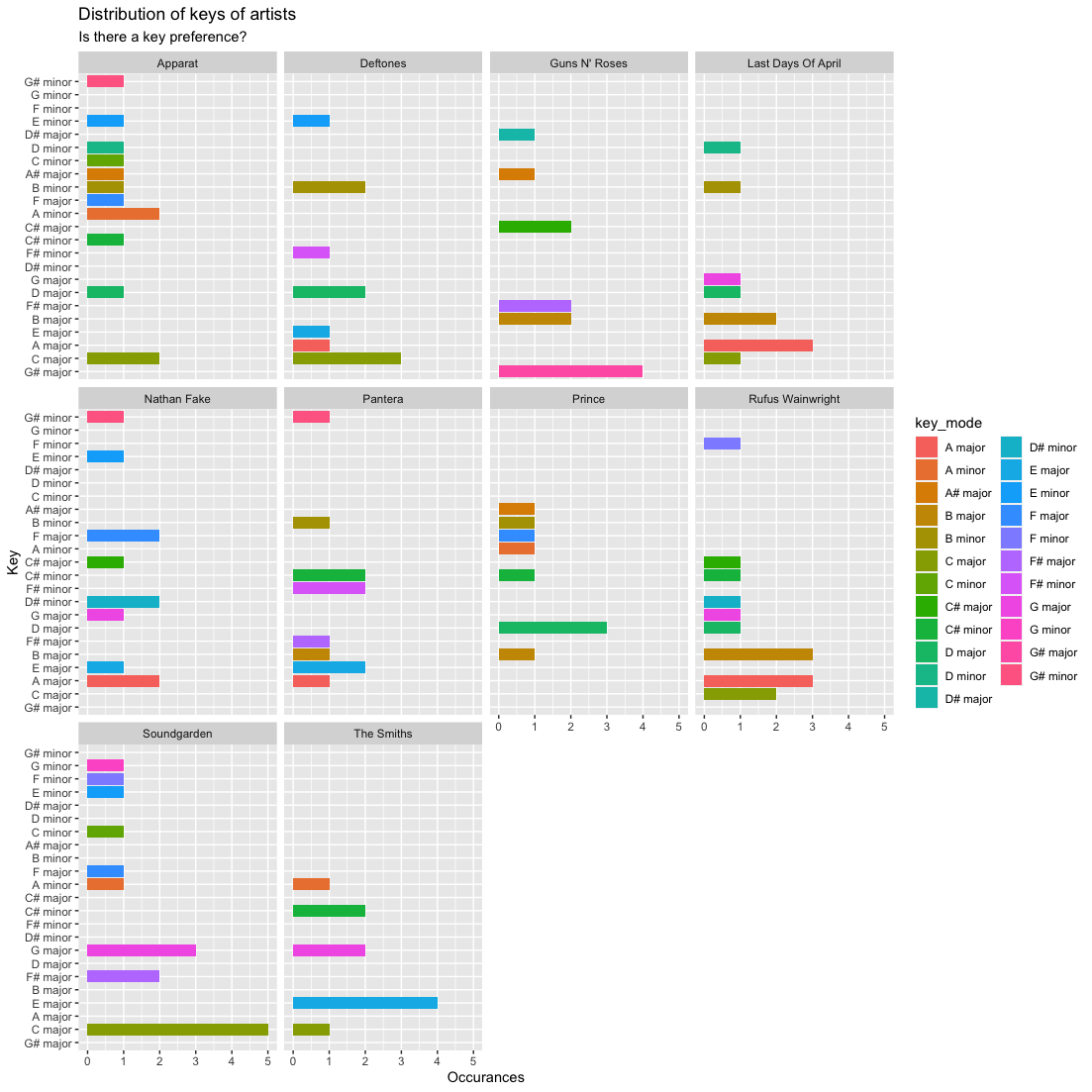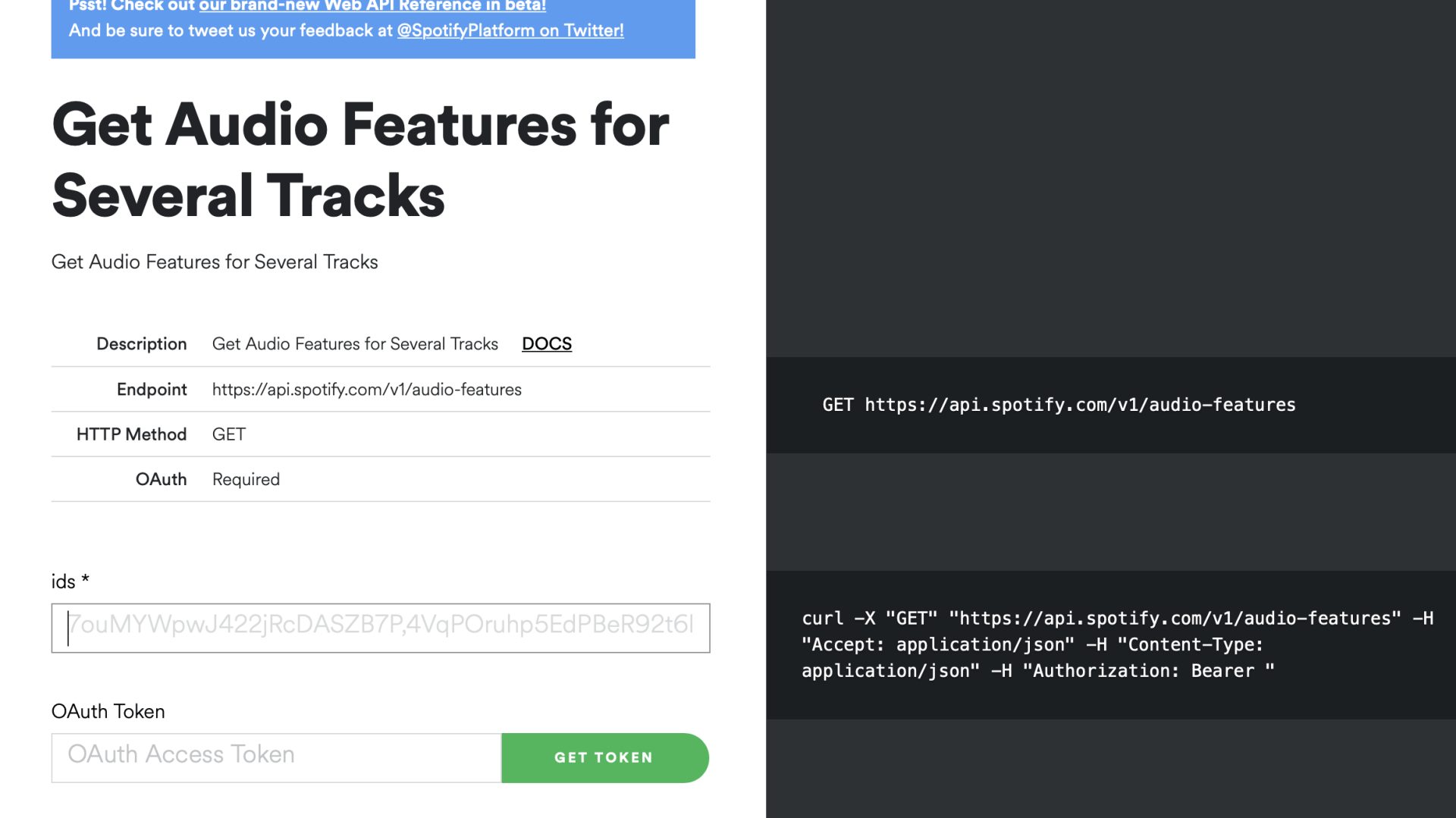

Managerial Implication
In my daily practice I see that the traditional data (science) lanscape witin organisations is changing. Were tradiotionaly your data science team was bound to a central data warehouse (and longer IT deliverly) that incorporated your company data - theres is now a noticeable trend towards a hybrid from with the use of connecting to API's
What are API's? API stands for API stands for Application Programming Interface. As Shana Pearlman desciribed it: "API is a software intermediary that allows two applications to talk to each other. In other words, an API is the messenger that delivers your request to the provider that you're requesting it from and then delivers the response back to you.
An API defines functionalities that are independent of their respective implementations, which allows those implementations and definitions to vary without compromising each other. Therefore, a good API makes it easier to develop a program by providing the building blocks.