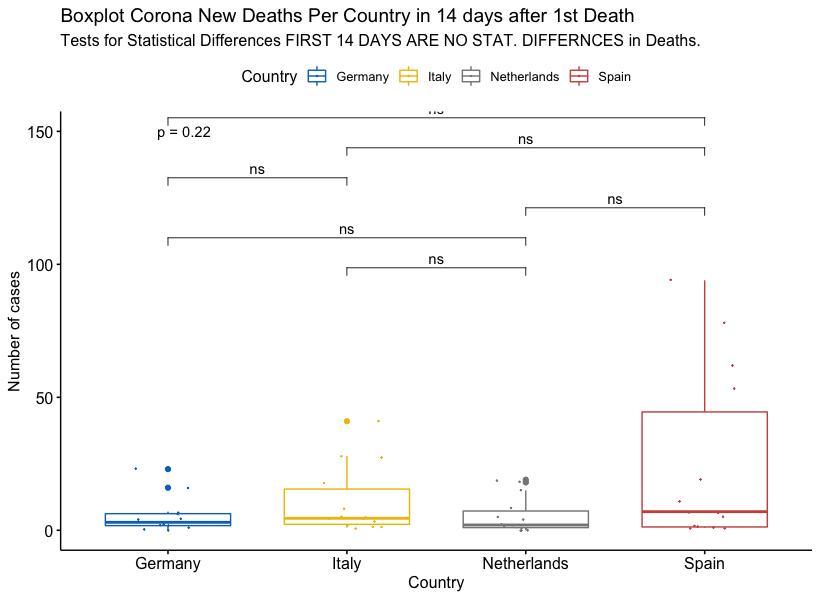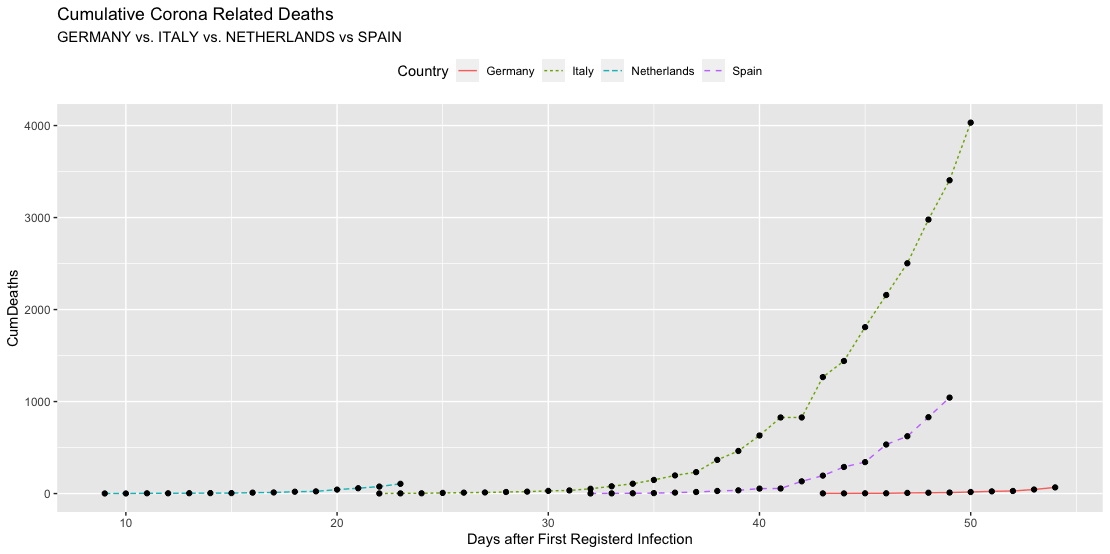
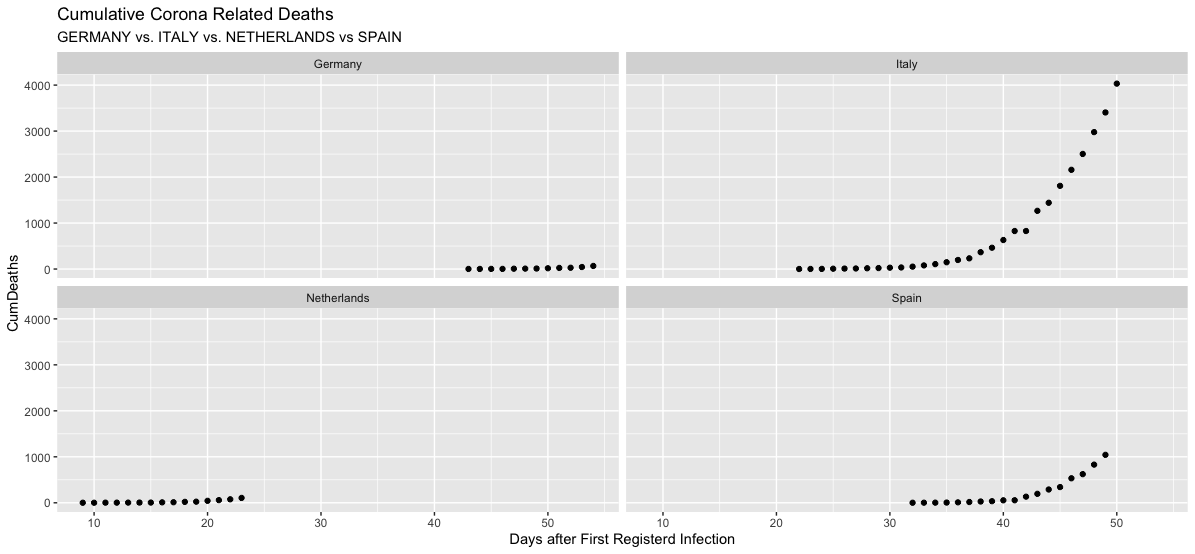
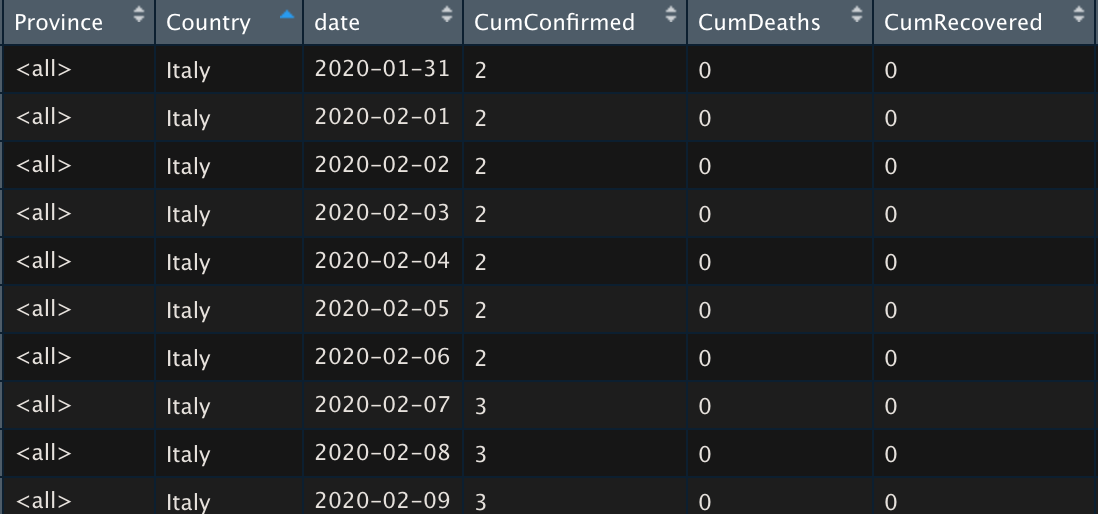

Managerial Implication
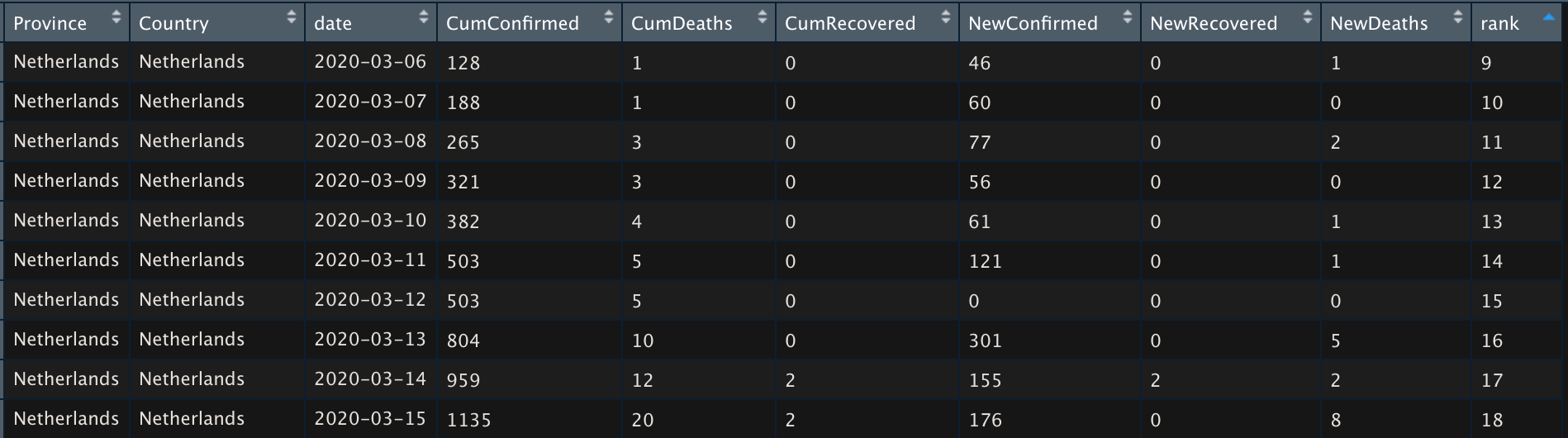
Based on the assumptions that Data Science initiatives generally develop according to analytical maturity frameworks - we are able to classify initivatives. (see table below)
This may help help in assesing your organisations analytical maturity. Where based on this assesment it is then possible to formulate an anlytical ambition and develop cooresponding roadmap(s) in order to achieve your ambition.