

Managerial Implication
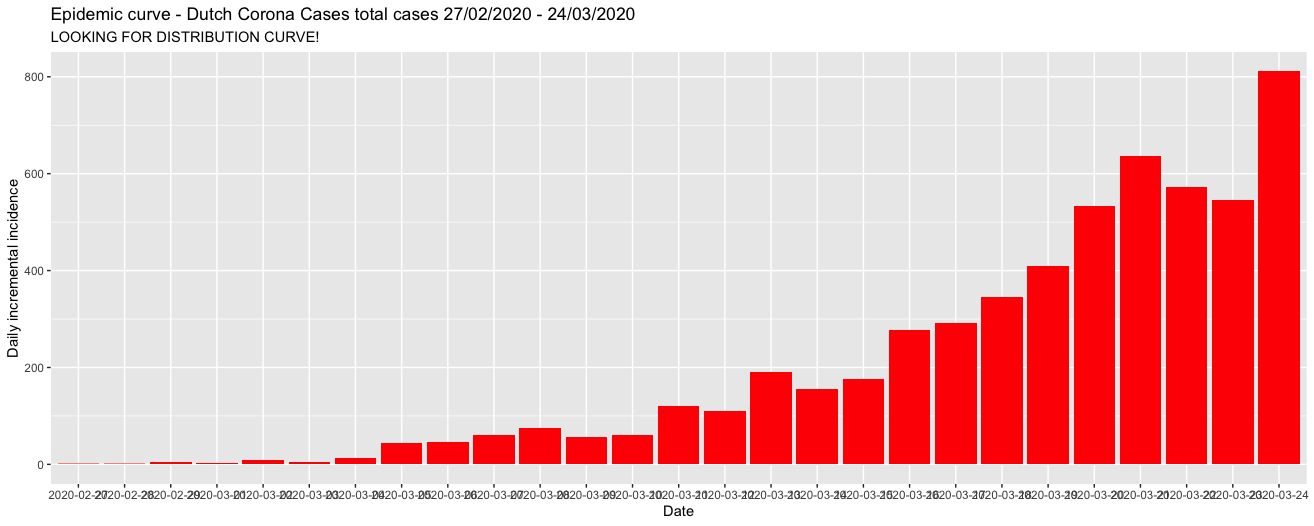
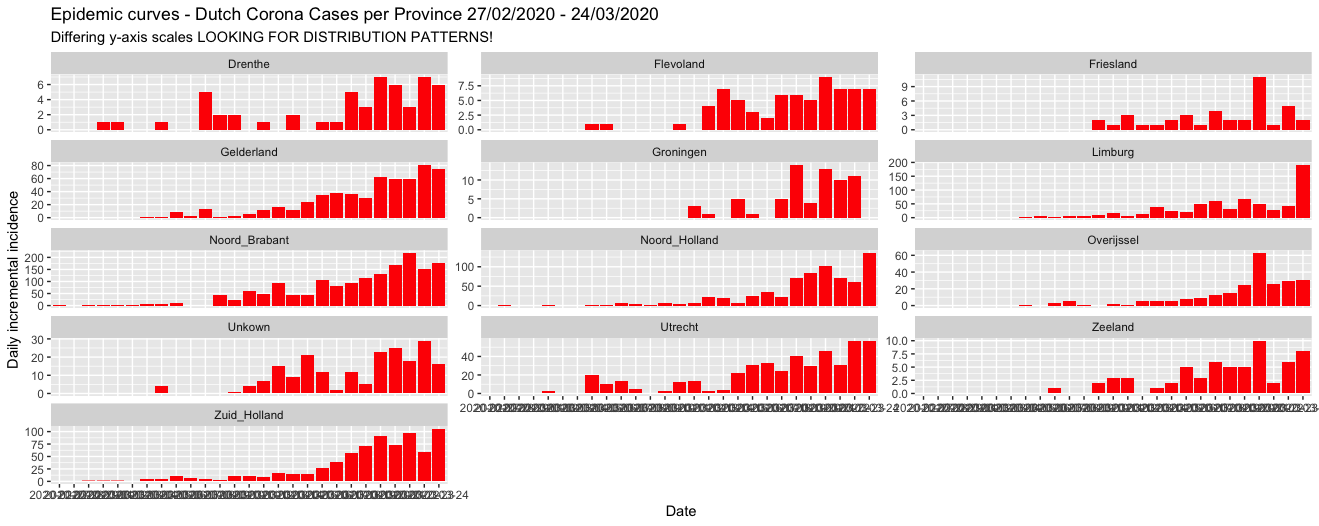
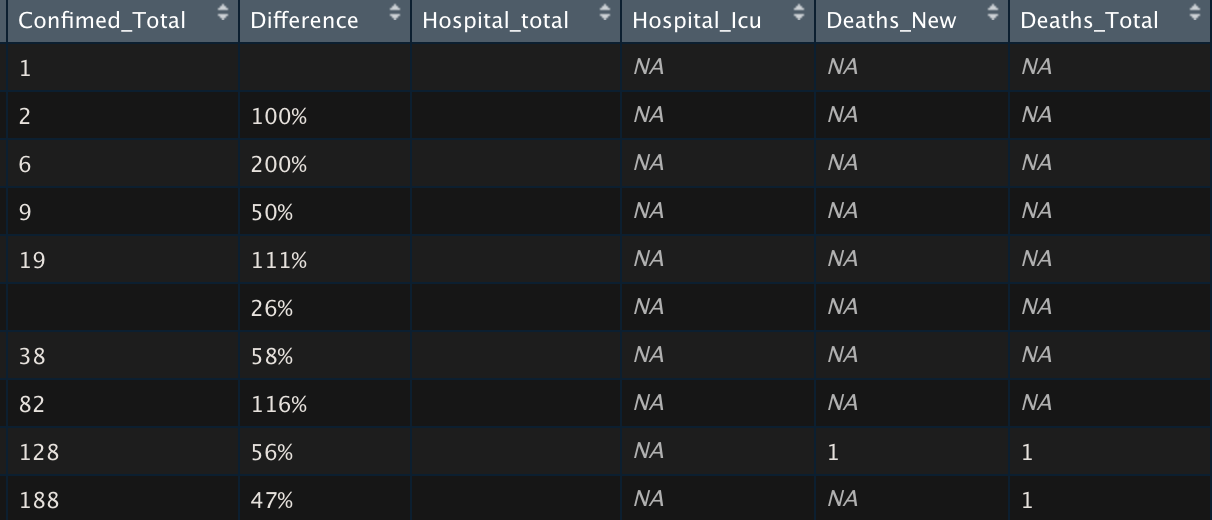
In general I like the iterative approach mentioned Now that all the data is loaded into the R environment we can start with the visual inspection of our data. However before that, and this might be a bit technical. We will need to transform our data to an appropriate unit levels. You might wonder why I am explaining this in detail. The reason is actually simpel and aimed for less 'data science / analytical' readers, where I would like to stress that 80% of the work generally goes into data collection and preparation and 20% consist of performing the analysis. (Good old Pareto's law)